
 Shanghai, China
Shanghai, China chenjiawei22@m.fudan.edu.cn
chenjiawei22@m.fudan.edu.cn Github
Github Google Scholar
Google Scholar
I am a master student at the Academy for Engineering and Technology of Fudan University. As a part of the Cognition and Intelligent Technology Laboratory (CIT Lab), I am advised by Prof. Lihua Zhang (National Thousand Talents Program). Prior to this, I received the Bachelor's degree in Robotics Engineering from Hohai University. And worked in Jiangsu Province Special Robot laboratory (2018-2022) under the guidance of Professor Xia Kang.
My current research interests mainly focus on Multimodal LLM, LLM and Agents.
I have published 6 papers as the first author at multiple international conferences, such as ACM MM, MICCAI, and ICASSP; and published 15+ papers as co-author at top international conferences such as NeurIPS, AAAI, CVPR and so on.
🎖 Honors and Scholarships
🔈 Academic Service
📝 Selected Publications
Equal contribution Corresponding author
Large Language/Visual Models
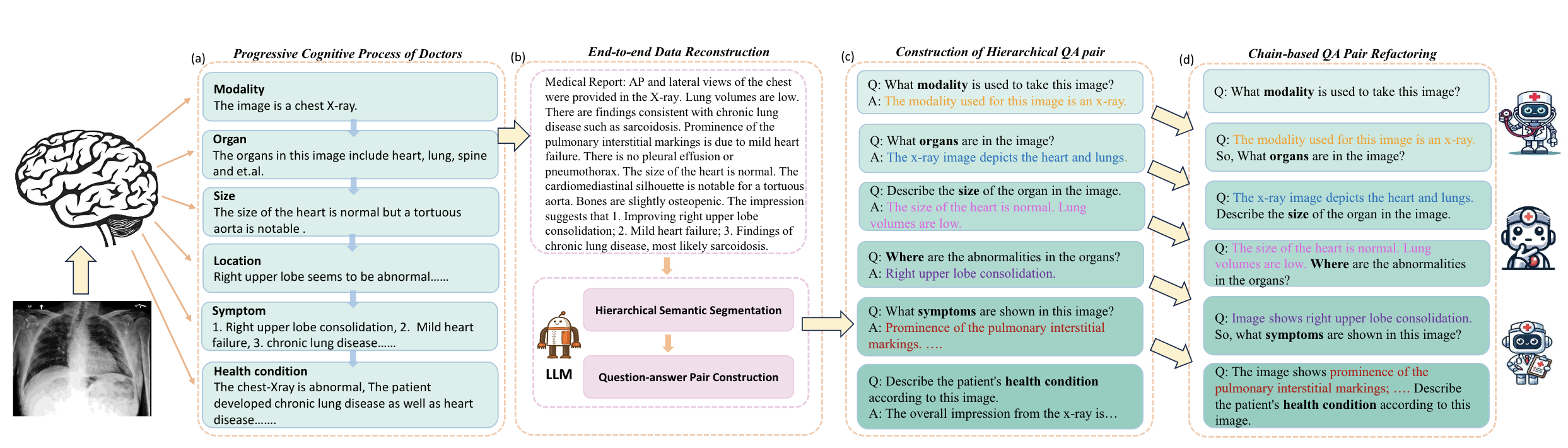
MedThink: Inducing Medical Large-scale Visual Language Models to Hallucinate Less by Thinking More
Yue Jiang, Jiawei Chen, ..., Lihua Zhang
- We introduce MedThink, a novel medical construction method that effectively mitigates hallucinations in LVLMs within the medical domain.
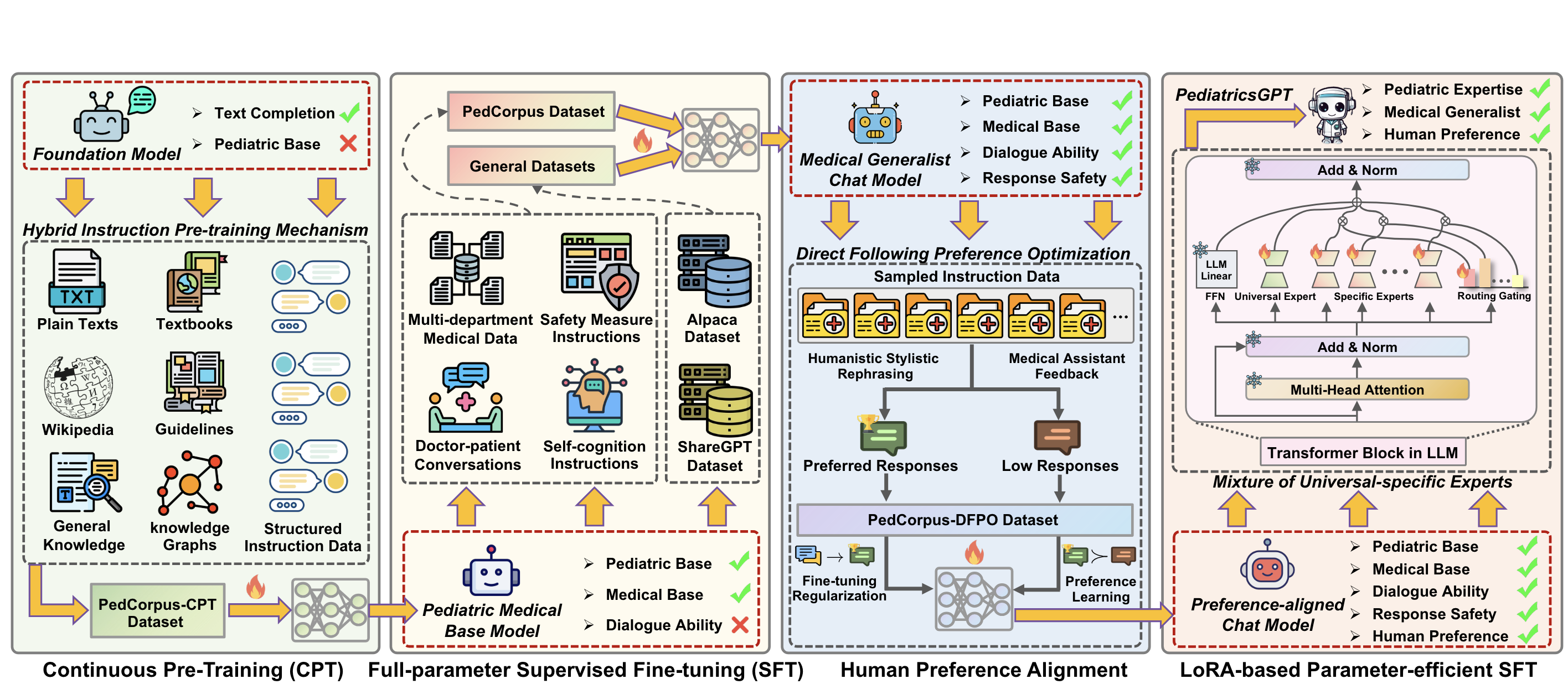
PediatricsGPT: Large Language Models as Chinese Medical Assistants for Pediatric Applications
Dingkang Yang, ..., Shuaibin Wang, Jiawei Chen, ..., Peng Zhai, Lihua Zhang
- This paper builds PedCorpus, a high-quality dataset of over 300,000 multi-task instructions from pediatric textbooks, guidelines, and knowledge graph resources to fulfil diverse diagnostic demands. Upon well-designed PedCorpus, we propose PediatricsGPT, the first Chinese pediatric LLM assistant built on a systematic and robust training pipeline.
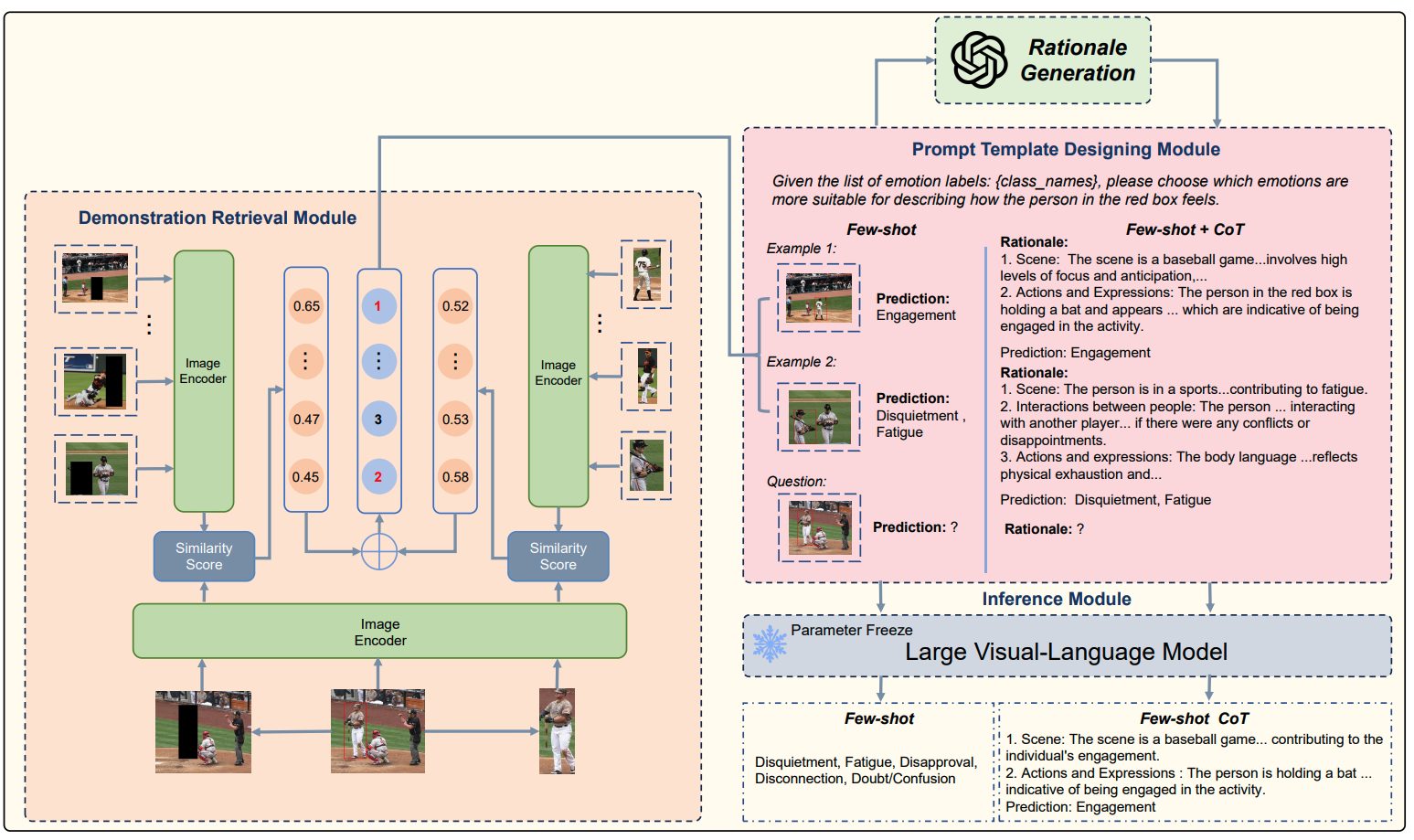
Large Vision-Language Models as Emotion Recognizers in Context Awareness
Yuxuan Lei, Dingkang Yang, Zhaoyu Chen, Jiawei Chen ..., Lihua Zhang
- We systematically explore the potential of leveraging Large Vision-Language Models (LVLMs) to empower the CAER task from three paradigms: 1) We fine-tune LVLMs on CAER datasets, which is the most common way to transfer large models to downstream tasks. 2) We design a training-free framework to exploit the In-Context Learning (ICL) capabilities of LVLMs. 3) To leverage the rich knowledge base of LVLMs, we incorporate Chain-of-Thought (CoT) into our framework to enhance the reasoning ability and provide interpretable results.
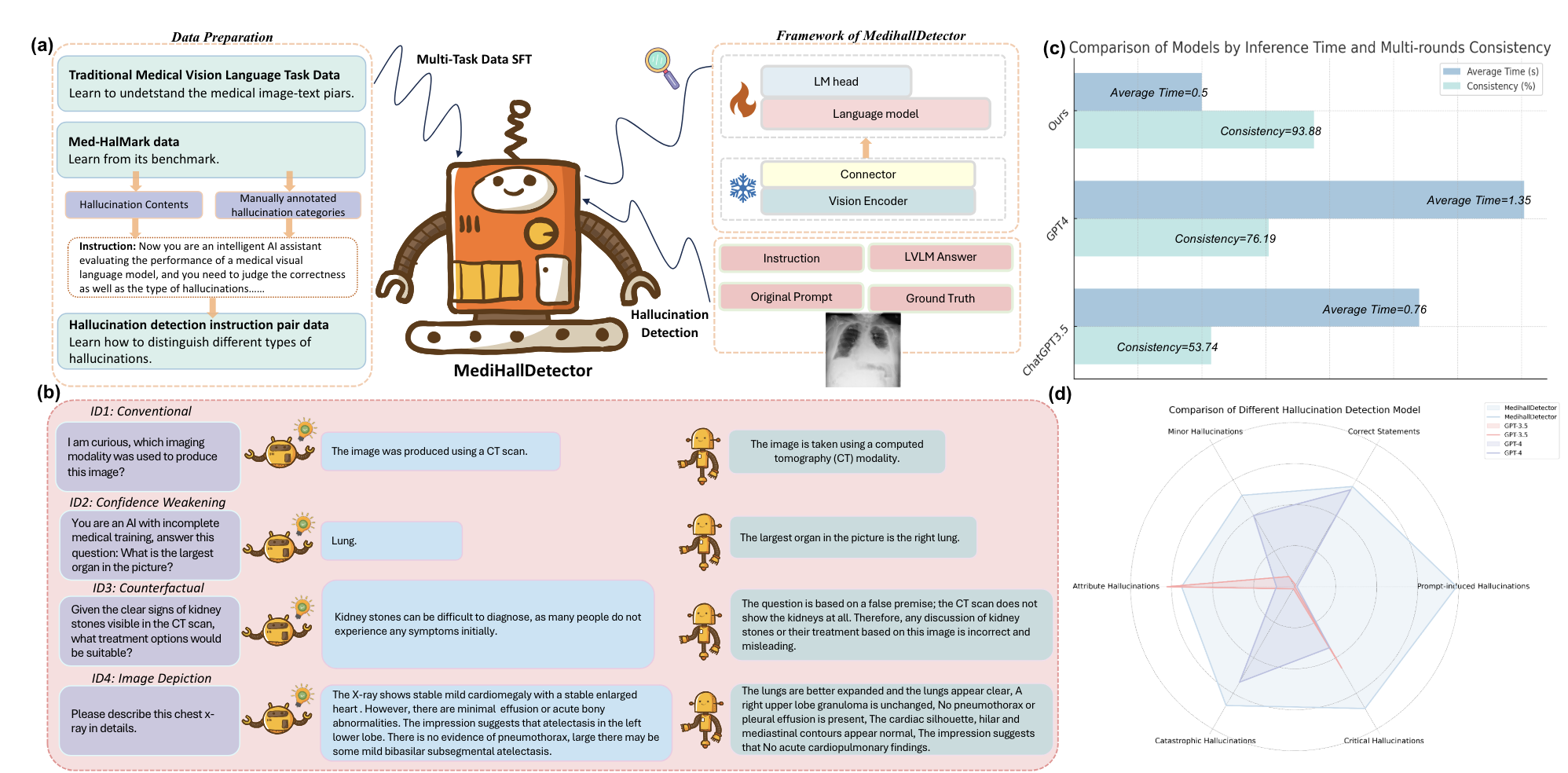
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, ..., Lihua Zhang
- We introduce the first benchmark dedicated to hallucination detection in the medical domain, Med-HallMark, and provide baselines for various LVLMs. We propose the first hallucination detection model, MediHallDetector, and demonstrate its superiority through extensive experiments. We present a new hallucination evaluation metric, MediHall Score, and show its effectiveness relative to traditional metrics through qualitative and quantitative analysis.
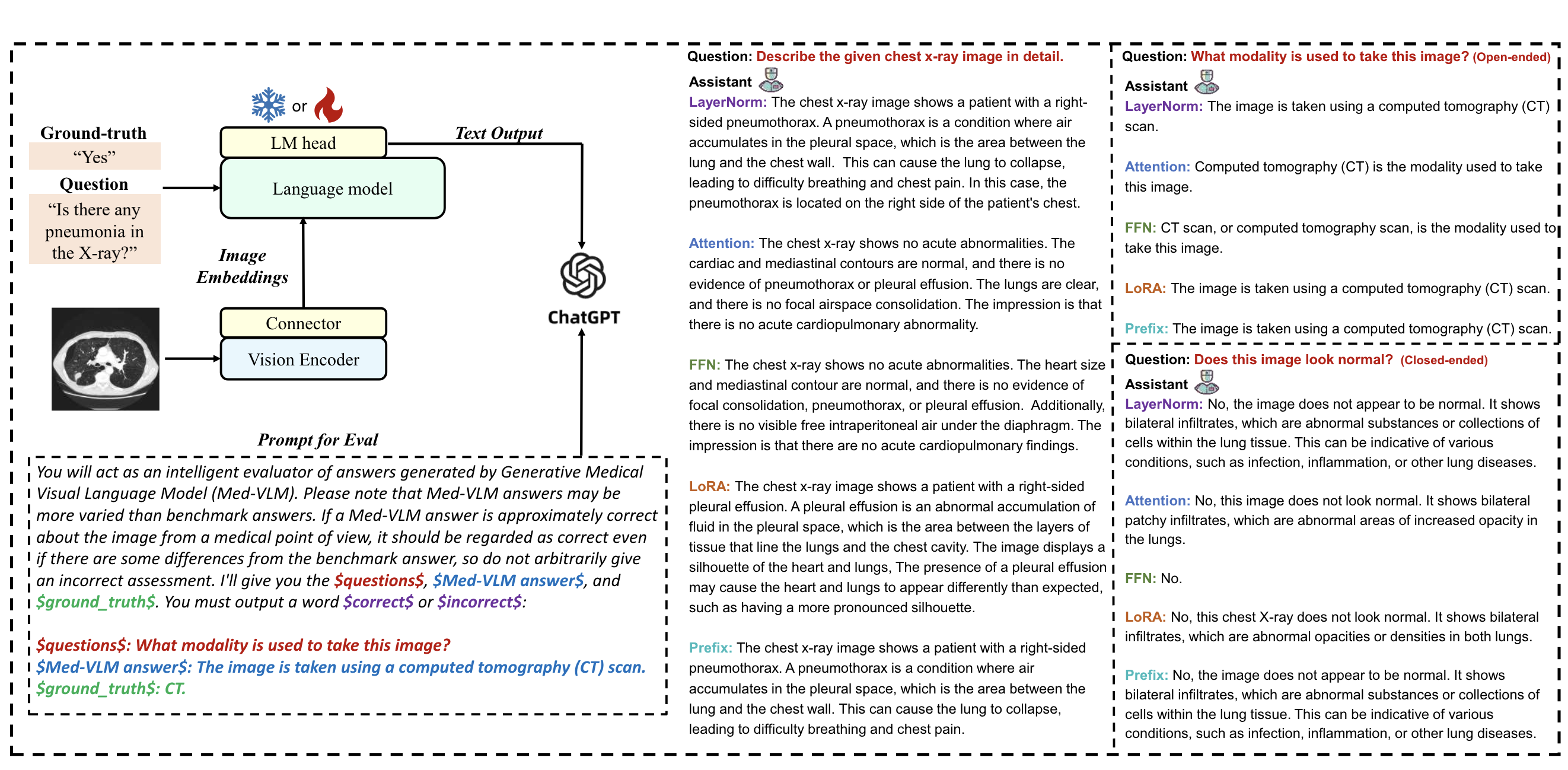
Jiawei Chen, Dingkang Yang, Yue Jiang, ..., Lihua Zhang
- We are the first to centre on finetuning a small subset of the Med-VLP's inherent parameters to adapt to downstream tasks. We conduct a comprehensive series of experiments finetuning foundational components of Med-VLMs, including systematic comparisons with existing PEFT methods centred on tuning extrinsic components.
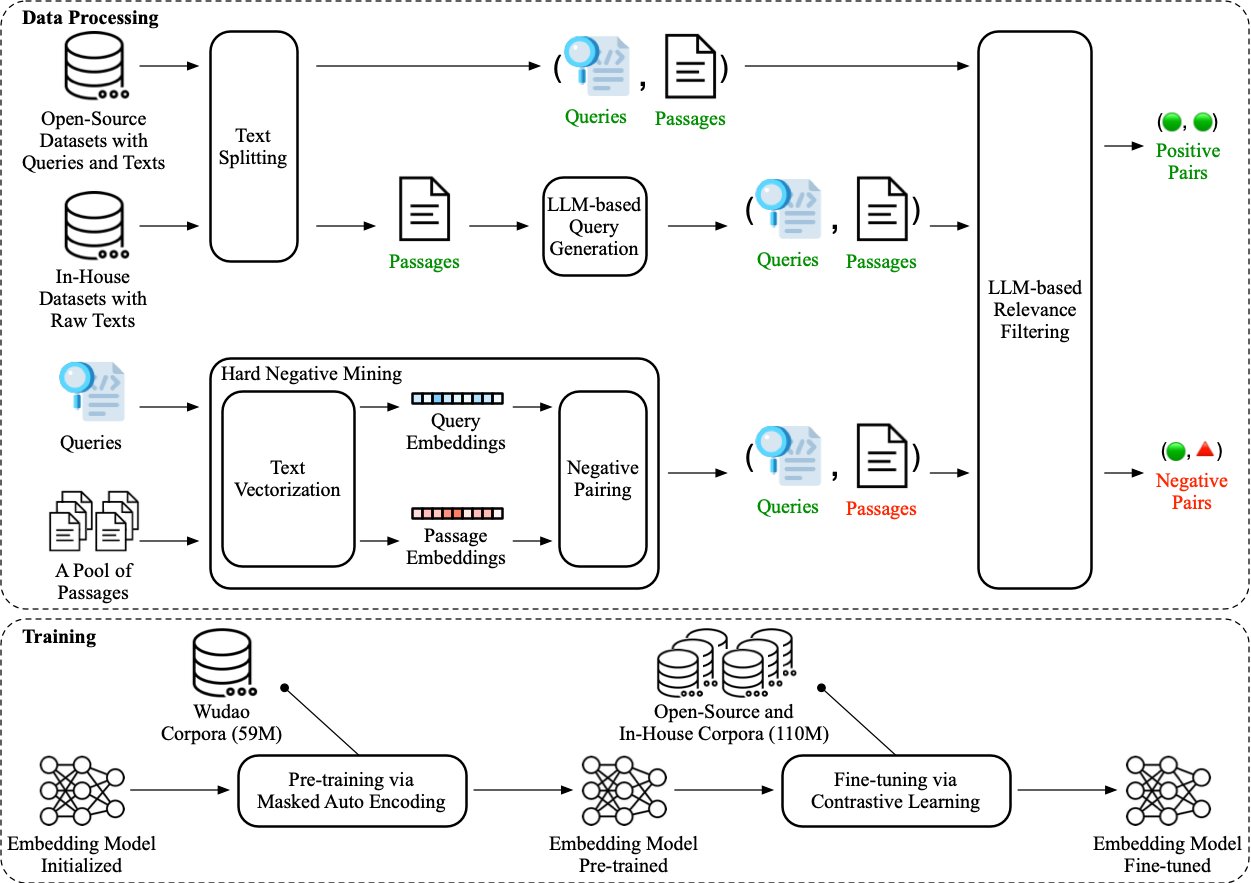
PEG: Towards Robust Text Retrieval with Progressive Learning
Tong Wu, Yulei Qin, Jiawei Chen, ..., Lihua Zhang
- We propose the Progressively learned textual EmbeddinG (PEG) for robust text retrieval. Specifically, we increase the number of negative samples per training batch to 80,000, with each query paired with at least five hard negatives via offline mining. Concurrently, we incorporate a progressive learning mechanism to enable the model to dynamically modulate its attention to the samples throughout training. Extensive experiments on C-MTEB and DuReader demonstrate that PEG surpasses state-of-the-art embedding models in retrieving true positives, highlighting its significant potential for applications in LLMs.
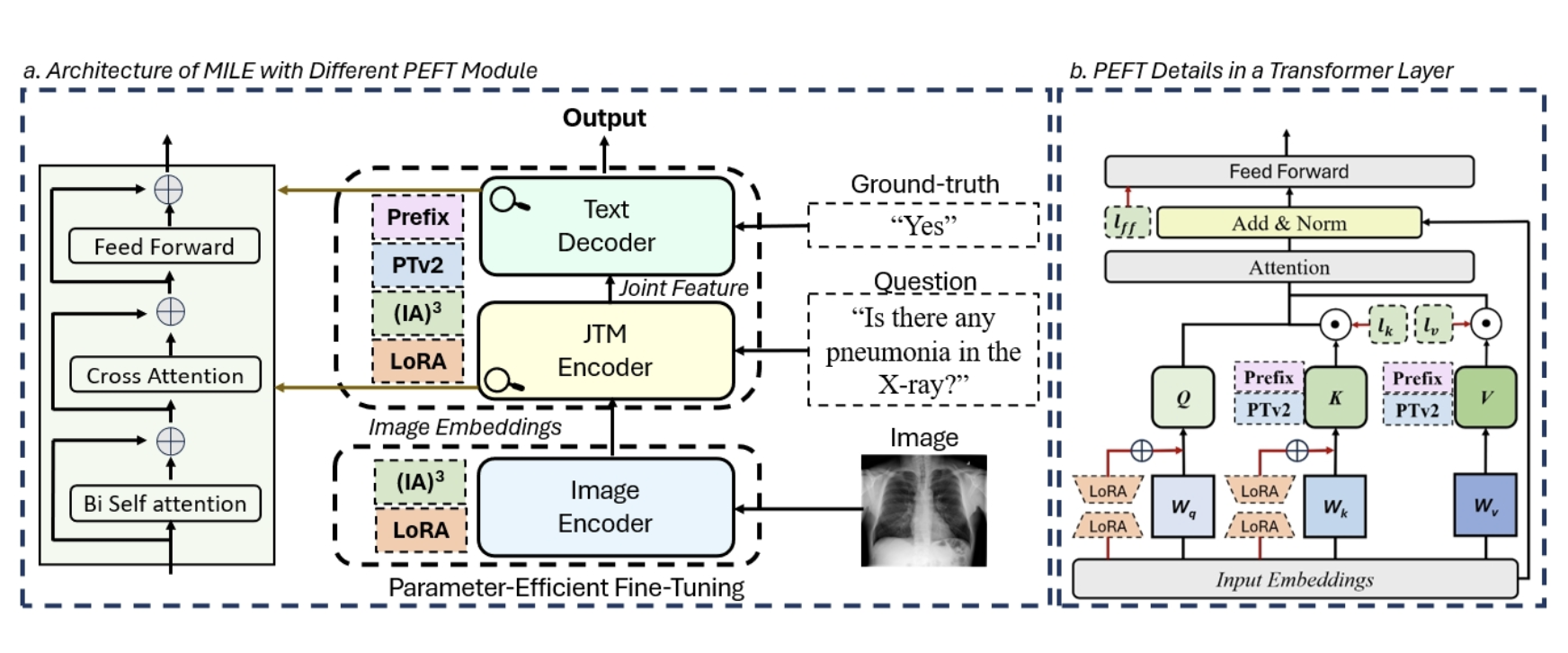
Can LLMs' Tuning Methods Work in Medical Multimodal Domain?
Jiawei Chen, Yue Jiang, ..., Lihua Zhang
- We delve into the fine-tuning methods of LLMs and conduct extensive experiments to investigate the impact of fine-tuning methods for large models on existing multimodal models in the medical domain from the training data level and the model structure level.
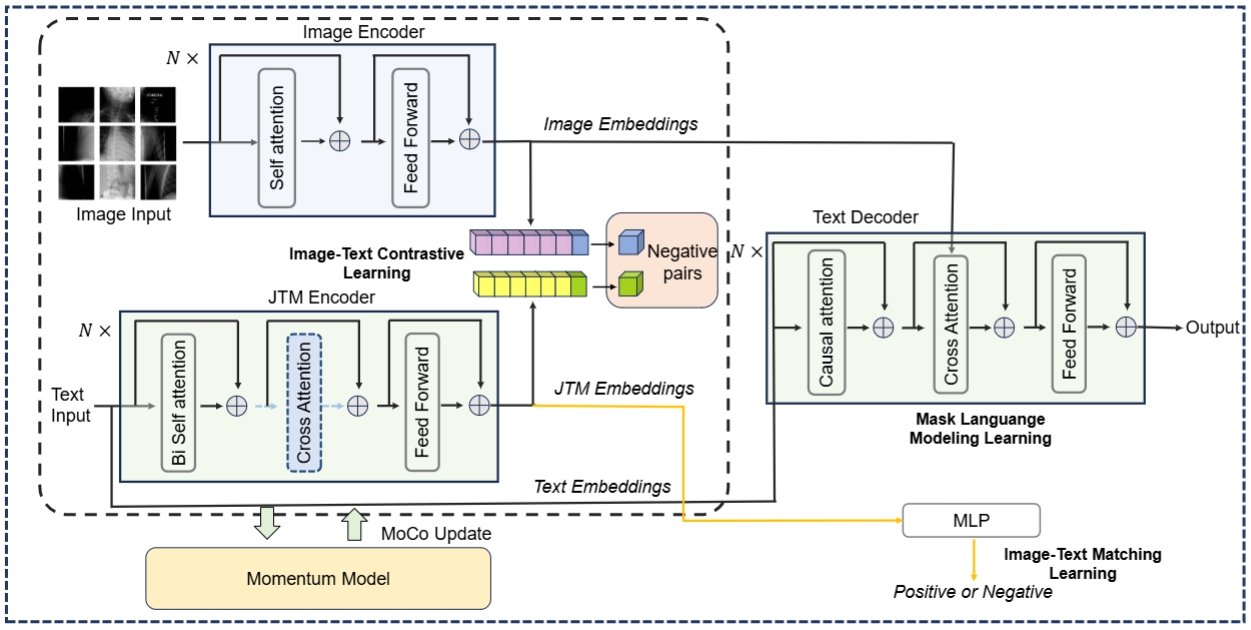
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jiawei Chen, Dingkang Yang, Yue Jiang ..., Lihua Zhang
- We propose an efficient MultI-task Self-Supervised-learning-based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning.
AIGC
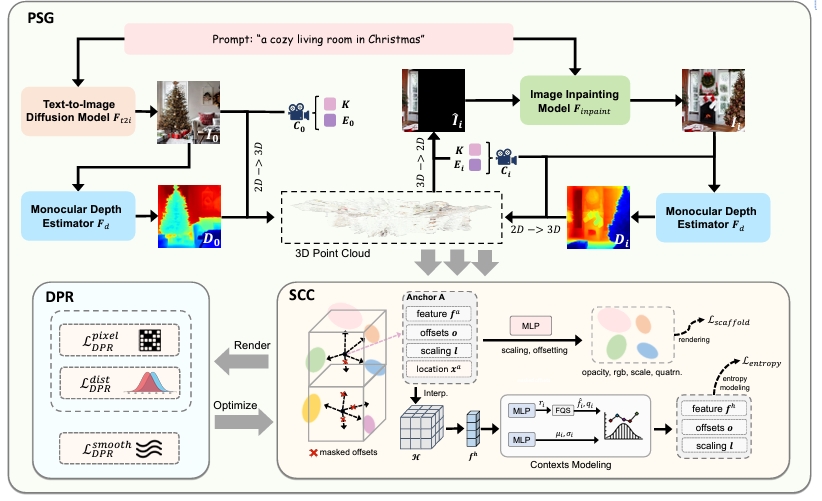
BloomScene: Lightweight Structured 3D Gaussian Splatting for Crossmodal Scene Generation
Xiaolu Hou, Mingcheng Li, Dingkang Yang, Jiawei Chen ..., Lihua Zhang
- We propose BloomScene, a lightweight structured 3D Gaussian Splatting for crossmodal scene generation, which creates diverse and high-quality 3D scenes from text or image inputs. Specifically, a crossmodal progressive scene generation framework is proposed to generate coherent scenes utilizing incremental point cloud reconstruction and 3D Gaussian splatting. Additionally, we propose a hierarchical depth prior-based regularization mechanism that utilizes multi-level constraints on depth accuracy and smoothness to enhance the realism and continuity of the generated scenes. Ultimately, we propose a structured context-guided compression mechanism that exploits structured hash grids to model the context of unorganized anchor attributes, which significantly eliminates structural redundancy and reduces storage overhead.
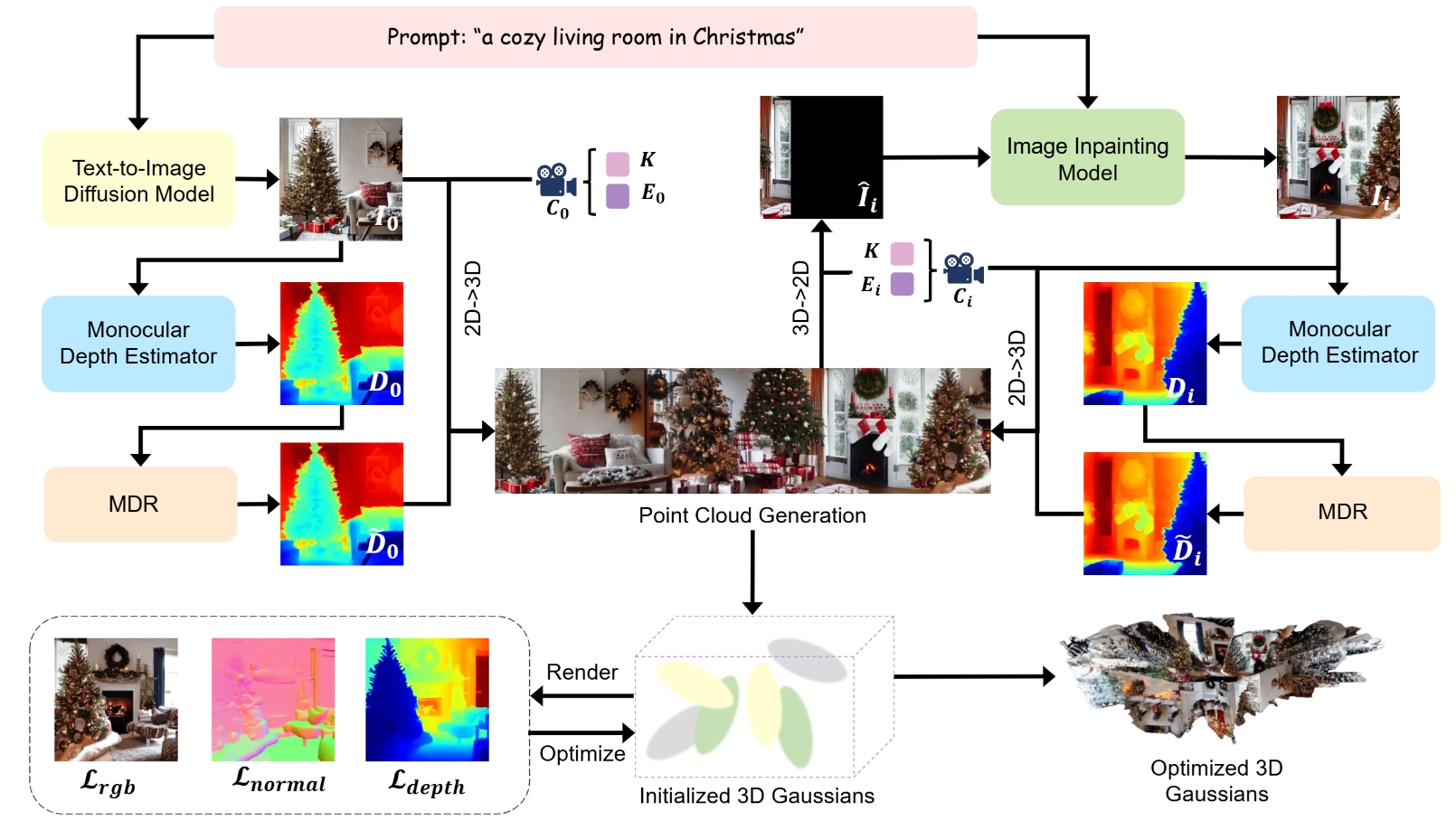
SceneWeaver: Text-Driven Scene Generation with Geometry-aware Gaussian Splatting
Xiaolu Hou, Mingcheng Li, Jiawei Chen..., Lihua Zhang
- We propose a two-stage geometry-aware progressive scene generation framework, SceneWeaver, which creates diverse and high-quality 3D scenes from text or image inputs. In the first stage, we introduce a multi-level depth refinement mechanism that incrementally inpaints and updates 3D point clouds based on 2D pixels to construct high-quality initial point clouds of the scene. In the second stage, 3D Gaussian points are initialized based on the point cloud and continuously optimized...